Demystifying Task-Transforms¶
Written by Varad Pimpalkhute on 02/18/2022.
Notebook of this tutorial is available on Colab Notebook.
In this tutorial, we will explore in depth one of the core utilities learn2learn library provides - Task Generators.
Overview¶
- We will first discuss the motivation behind generating tasks. (Those familiar with meta-learning can skip this section.)
- Next, we will have a high-level overview of the overall pipeline used for generating tasks using
learn2learn. MetaDatasetis used fast indexing, and accelerates the process of generating few-shot learning tasks.UnionMetaDatasetandFilteredMetaDatasetare extensions ofMetaDatasetthat can further provide customised utility.UnionMetaDatasetbuilds up onMetaDatasetto construct a union of multiple input datasets, andFilteredMetaDatasettakes in aMetaDatasetand filters it to include only the required labels.TaskDatasetis the core module that generates tasks from input dataset. Tasks are lazily sampled upon indexing or calling.sample()method.- Lastly, we study different
task transformsdefined inlearn2learnthat modifies the input data such that a customisedtaskis generated.
Motivation for generating tasks¶
What is a task?¶
Let's first start with understanding what is a task. The definition of a task varies from one application to other, but in context of few-shot learning, a task is a supervised-learning approach (e.g., classification, regression) trained over a collection of datapoints (images, in context of vision) that are sampled from the same distribution.
For example, a task may consist of 5 images from 5 different classes - flower, cup, bird, fruit, clock (say, 1 image per class), all sampled from the same distribution. Now, the objective of the task might be to classify the images present at test time amongst the five classes - that is, minimize over the loss function.
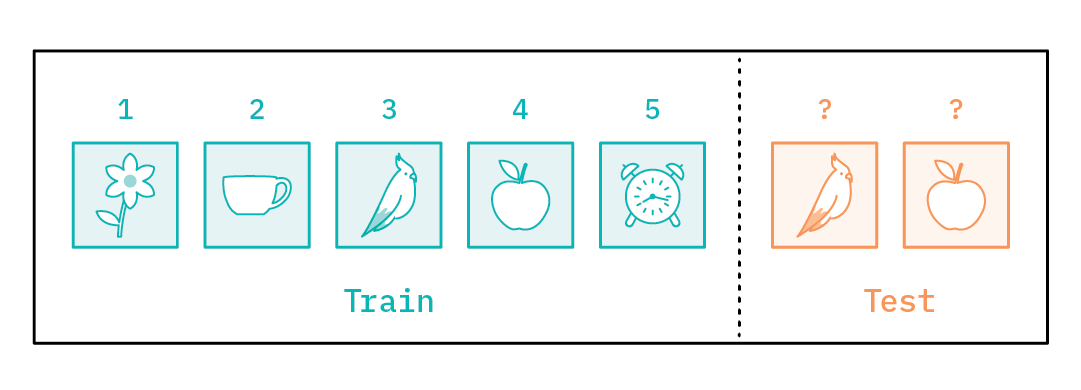
How is a task used in context of meta-learning?¶
Meta-learning used in the context of few-shot learning paradigm trains over different tasks (each task consists of limited number of samples) over multiple iterations of training. For example, gradient-based meta-learners learn a model initialization prior such that the model converges to the global minima on unseen tasks (tasks that were not encountered during training) using few samples/datapoints.
How is a task generated?¶
In layman's terms, few-shot classification experiment is set up as a N-wayed K-shot problem. Meaning, the model needs to learn how to classify an input task over N different classes given K examples per class during training. Thus, we need to generate 'M' such tasks for training, and inferencing the meta-learner.
Summarizing, we require to:
- Iterate over classes and their respective samples present in the dataset rapidly in order to generate a task.
- Write a protocol that generates a task that adhers to the few-shot paradigm (that is,
N-way K-shotproblem). - Incorporate additional transforms (say, augmentation of data).
- Generate
Mrandomly sampled tasks for training and inferencing.
Given any input dataset, learn2learn makes it easy for generating custom tasks depending on the user's usecase.
1 2 3 4 5 6 7 8 | |
Overview of pipeline for generating tasks¶
Given any input dataset, learn2learn makes it easy for generating custom tasks depending on the user's usecase. A high-level overall pipeline is shown in the diagram below:
The dataset consists of 100 different classes, having 5 samples per class. The objective is to generate N-wayed K-shot task (say, 3-way 2-shot task from the given dataset.)
![]()
The below code snippet shows to generate customised tasks using any input custom using learn2learn.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
(out): torch.Size([5, 1, 28, 28])
And that's it! You have now generated one task randomly sampled from the omniglot dataset distribution. For generating M tasks, you will need to sample the taskset M times.
For the rest of the tutorial, we will inspect each of the modules present in the above code, and discuss a few general strategies that can be used while generating tasks efficiently.
MetaDataset - A wrapper for fast indexing of samples.¶
At a high level, MetaDataset is a wrapper that enables fast indexing of samples of a given class in a dataset. The motivation behind building is to decrease the time to everytime we iterate over a dataset to generate tasks. Naturally, the time saved increases as the dataset size keeps on increasing.
Note : The input dataset needs to be iterable.
learn2learn does this by maintaining two dictionaries for each classification dataset:
1. labels_to_indices: A dictionary that maintains labels of classes as keys, and the corresponding indices of samples within the class in form of list as values.
2. indices_to_labels: As the name suggests, a dictionary is formed with indices of samples as key, and their corresponding class labels as value.
This feature comes in handy while generating tasks. For example, if you are sampling a task having N classes (say, N=5), then using labels_to_indices dictionary to identify all the samples belonging to this set of 5 classes () will be much more faster than iterating all the samples ().
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Any one of the two dictionaries can also be optionally passed as an argument upon instantiation, and the other dictionary is built using this dictionary (See Line 81 - Line 90 on GitHub.)
Bookkeeping¶
learn2learn also provides another utility in the form of an attribute _bookkeeping_path. If the input dataset has the given attribute, then the built attributes (namely, the two dictionaries, and list of labels) will be cached on disk for latter use. It is recommended to use this utility if:
- If the dataset size is large, as it can take hours for instantiating it the first time.
- If you are going to use the dataset again for training. (Iterating over all the samples will be much slower than loading it from disk)
To use the bookkeeping utility, while loading your custom dataset, you will need to add an additional attribute to it.
For example, we add _bookkeeping_path attribute while generating FC100 dataset as follows:
self._bookkeeping_path = os.path.join(self.root, 'fc100-bookkeeping-' + mode + '.pkl')
where, mode is either train, validation, or test (depends on how you are defining your dataset. It's also possible that you are loading the entire dataset, and then creating train-valid-test splits. In that case, you can remove the mode variable)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
(out): labels_to_indices: label as keys, and list of sample indices as values defaultdict(
, {0: [0, 1, 2, 3, 4, ..., 16, 17, 18, 19], 1: [20, 21, 22, 23, 24, 25, ..., 28, 29], ..., 1622: [32440, 32441, 32442, 32443, 32444, ..., 32458, 32459]}) indices_to_labels: index as key, and corresponding label as value defaultdict(
, {0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6, ..., 32458: 1622, 32459: 1622})
So far, we understood the motivation for using MetaDataset. In the next sections, we will discuss exactly how the dictionaries generated using MetaDataset are used for creating a task.
UnionMetaDataset - A wrapper for multiple datasets¶
UnionMetaDataset is an extension of MetaDataset, and it is used to merge multiple datasets into one. This is useful when you want to sample heterogenous tasks - tasks in a metabatch being from different distributions.
learn2learn implements it by simply remapping the labels of the dataset in a consecutive order. For example, say you have two datasets: : {1600 labels, 32000 samples} and : {400 labels, 12000 samples}. After wrapping the datasets using UnionMetaDataset we will get a MetaDataset that will have 2000 labels and 44000 samples, where the initial 1600 labels (0, 1, 2, ..., 1599) will be from and (1600, 1601, ..., 1999) labels will be from . Same is the case for the indices of the union.
A list of datasets is fed as input the
UnionMetaDataset
Below code shows how a high level implementation of the wrapper:
1 2 3 4 5 6 7 8 | |
1 2 3 4 | |
(out): Union was successful
To retrieve a data sample using index, UnionMetaDataset iterates over all the individual datasets as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
(out): 1670
FilteredMetaDataset - Filter out unwanted labels¶
FilteredMetaDataset is a wrapper that takes in a MetaDataset and filters it to only include a subset of the desired labels.
The labels included are not remapped, and the label value from the original dataset is retained.
1 2 3 4 5 | |
TaskDataset - Core module¶
Introduction¶
This is one of the core module of learn2learn that is used to generate a task from a given input dataset. It takes dataset, and list of task transformations as arguments. The task transformation basically define the kind of tasks that will be generated from the dataset. (For example, KShots transform limits the number of samples per class in a task to K samples per class.)
If there are no task transforms, then the task consists of all the samples in the entire dataset.
Another argument that TaskDataset takes as input is num_tasks (an integer value). The value is set depending on how many tasks the user wants to generate. By default, it is kept as -1, meaning infinite number of tasks will be generated, and a new task is generated on sampling. In the former case, the descriptions of the task will be cached in a dictionary such that if a given task is called again, the description can be loaded instantly rather than generating it once again.
What is a task description?¶
A task_description is a list of DataDescription objects with two attributes: index, and transforms. Index corresponds to the index of a sample in the dataset, and transforms is a list of transformations that will be applied to the sample.
1 2 3 4 5 6 7 8 9 10 11 | |
How is a task generated?¶
STEP 1
An index between [0, num_tasks) is randomly generated.\
(If num_tasks = -1, then index is always 0.)
1 2 3 4 5 6 7 | |
STEP 2
There are two possible methods for generating task_description:
-
If there's a cached description for the given index, the
task_descriptionis assigned the cached description. -
Otherwise, each transform takes the description returned by the previous transform as argument, and in turn returns a new description.
The above only holds true when
num_tasks != -1, fornum_tasks = -1, new description is computed every time.NOTE - It is to be noted
task_descriptionanddata_descriptionare general methods and can be used for any type of task, be it a classification task, regression task, or even a timeseries task.
Below code discusses both the methods.
1 2 3 4 5 6 7 | |
1 2 3 4 5 6 7 8 9 10 11 | |
STEP 3
Once a task_description is retrieved/generated, task is generated by applying the list of transformations present in each of the DataDescription objects in the task description list.
The transformations mentioned above are different from
task_transforms(task_transformsexamples:NWays,KShots,LoadData, etc.)
All the data samples generated in the list are accumulated and collated using task_collate. (by default, task_collate is assigned collate.default_collate)
DataDescription object has two attributes:
index of the sample and any transforms that need to be applied on the sample.
1 2 3 4 5 6 7 8 9 10 11 | |
We will be discussing more about the data_description.transforms in the next section, after which there will be more clarity on exactly how the above snippet modifies the data.
A few general tips¶
-
If you have not wrapped the dataset with
MetaDatasetor its variants, the function will automatically instantiateMetaDatasetwrapper. -
If you are not sure how many tasks you want to generate, use
num_tasks = -1. -
If
num_tasks = N, and you are samplingMtasks whereM > N, thenM - Ntasks will definitely be repeated. In case you want to avoid it, make sureN >= M. -
Given a list of task transformations, the transformations are applied in the order they are listed. (Task generated using transforms might be different from that generated using .
-
A
taskis lazily sampled upon indexing, or using.sample()..sample()is equivalent to indexing, just that before indexing, it randomly generates an index to be indexed. -
When using
KShotstransform, query twice the samples required for training. The queried samples will need to be split in half, for training, and evaluation.learn2learnprovides a nice utility calledpartition_task()to partition the data in support and query sets. Check this to know more about it. A quick use case:
1 2 | |
task_descriptionanddata_descriptionare general methods and can be used for any type of task, be it a classification task, regression task, or even a timeseries task.
In the next section, we will examine how the task_transforms exactly modify the input dataset to generate a task.
1 2 3 4 | |
Task Tranforms - Modifying the input dataset¶
Task transforms are a set of transformations that decide on what kind of a task is generated at the end. We will quickly go over some of the transforms defined in learn2learn, and examine how they are used.
To reiterate, a DataDescripton is a class that has two attributes: index, and transforms. Index stores the index of the data sample, and transforms stores list of transforms if there are any (transforms is different from task transforms). In layman's words, it stores indices of samples in the dataset.
Only
LoadDataandRemapLabelsadd transforms in the list of transform attribute inDataDescriptionobject.
High-Level Interface¶
Each of the task transform classes is inherited from TaskTranform class. All of them have a common skeleton in the form of three methods namely: __init__(), __call__() and new_task().
We will now discuss what each of these methods do in general.
__init__() Method
Initializes the newly created object, in the transform, while also inheriting some arguments such as the dataset from the parent class. Objects / variables that needed to be instantiated only again are defined here.
__call__() Method
It's a callable method, and is used as a function to write the task_transform specific functionality. Objects / variables that keep on changing are defined here.
new_task() Method
If the task_description is empty (that is, None), then this method is called. This method loads all the samples present in the dataset to the task_description. For instance, check the code below. It loads all the samples present in the dataset to the task_description
1 2 3 4 5 6 | |
A) FusedNWaysKShots¶
Efficient implementation of KShots, NWays, and FilterLabels transforms. We will be discussing each of the individual transforms in the subsequent sections.
If you are planning to make use of more than 1 or these transforms, it is recommended to make use of FusedNWaysKshots transform instead of using each of them individually.
B) NWays¶
Keeps samples from N random labels present in the task description. NWays iterate over the current task description to generate a new description as follows:
- If no
task_descriptionis available,NWaysrandomly samplesNlabels, and adds all the samples in theseNrandom labels usinglabels_to_indicesdictionary. - Else, using
indices_to_labelsdictionary, it first identifies the unique labels present in the description. Next, it randomly samplesNlabels from the set of classes. - Lastly, it iterates over all the indices present in the description. If the
indexbelongs to the set of theseNrandom labels, the sample is added in the newtask_description.
1 2 3 4 5 6 7 8 9 10 11 | |
(out): [14380, 14381, 14382, ..., 31196, 31197, 31198, 31199] Number of samples: 100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
C) KShots¶
It samples K samples per label from all the labels present in the task_desription. Similar to NWays, KShots iterate over the samples present in the current task_description to generate a new one:
- If
task_descriptionisNone, load all the samples present in the dataset. - Else, generate a
class_to_datadictionary that stores label as key and corresponding samples as value. - Lastly,
Ksamples are sampled from each of the classes either with or without replacement.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
(out): 3246
D) LoadData¶
Loads a sample from the dataset given its index. Does so by appending a transform lambda x: self.dataset[x] to transforms attribute present in DataDescription for each sample.
1 2 3 | |
The above three task transforms are the main transforms that are usually used when generating few-shot learning tasks. These transforms can be used in any other.
E) FilterLabels¶
It's a simple transform that removes any unwanted labels from the task_description. In addition to the dataset, it takes a list of labels that need to be included as an argument.
- It first generates filtered indices that keep a track on all the indices of the samples from the input labels.
- Next, it iterates over all the indices in the task description, and filters them out if they don't belong to the filtered indices.
If you are using FilterLabels transform, it is recommended to use it before NWays, and KShots transforms.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
F) ConsecutiveLabels¶
The transform re-orders the samples present in the task_description according to the label order consecutively. If you are using RemapLabels transform and keeping shuffle=True, it is recommended to keep ConsecutiveLabels tranform after RemapLabels, otherwise, while they will be homogeneously clustered, the ordering would be random. If you are using ConsecutiveLabels transform before RemapLabels, and want ordered set of labels, then keep shuffle=False.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
(out): [271, 702, 756, 319, 948, 840, 843, 741, 89, 413] [13, 33, 34, 46, 56, 57, 62, 70, 76, 92]
G) RemapLabels¶
The transform maps the labels of input to 0, 1, ..., N (given N unique set of labels).
For example, if input task_description consists of samples from 3 labels namely 71, 14 and 89, then the transform maps the labels to 0, 1 and 2. Compulsorily needs to be present after LoadData transform in the transform list, otherwise, will give a TypeError: int is not iterable.
The error occurs because RemapLabels expects the input to be of iterable form. Thus, unless you load data using LoadData prior to it, it will try to iterate over sample index, which is an int, and not an iterable.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 3 4 5 6 7 8 9 | |
Conclusion¶
Thus, we studied how learn2learn simplifies the process of generating few-shot learning tasks. For more details, have a look at:
learn2learn provides benchmarks for some of the commonly used computer vision datasets such as omniglot, fc100, mini-imagenet, cirfarfs and tiered-imagenet. The benchmarks are available at this link.
They are very easy to use, and can be used as follows:
1 2 3 4 5 6 | |
If you have any other queries - feel free to ask questions on the library's slack channel, or open an issue here.
Thank you!