Meta-Reinforcement Learning¶
Warning
Meta-RL results are particularly finicky to compare. Different papers use different environment implementations, which in turn produce different convergence and rewards. The plots below only serve to indicate what kind of performance you can expect with learn2learn.
MAML¶
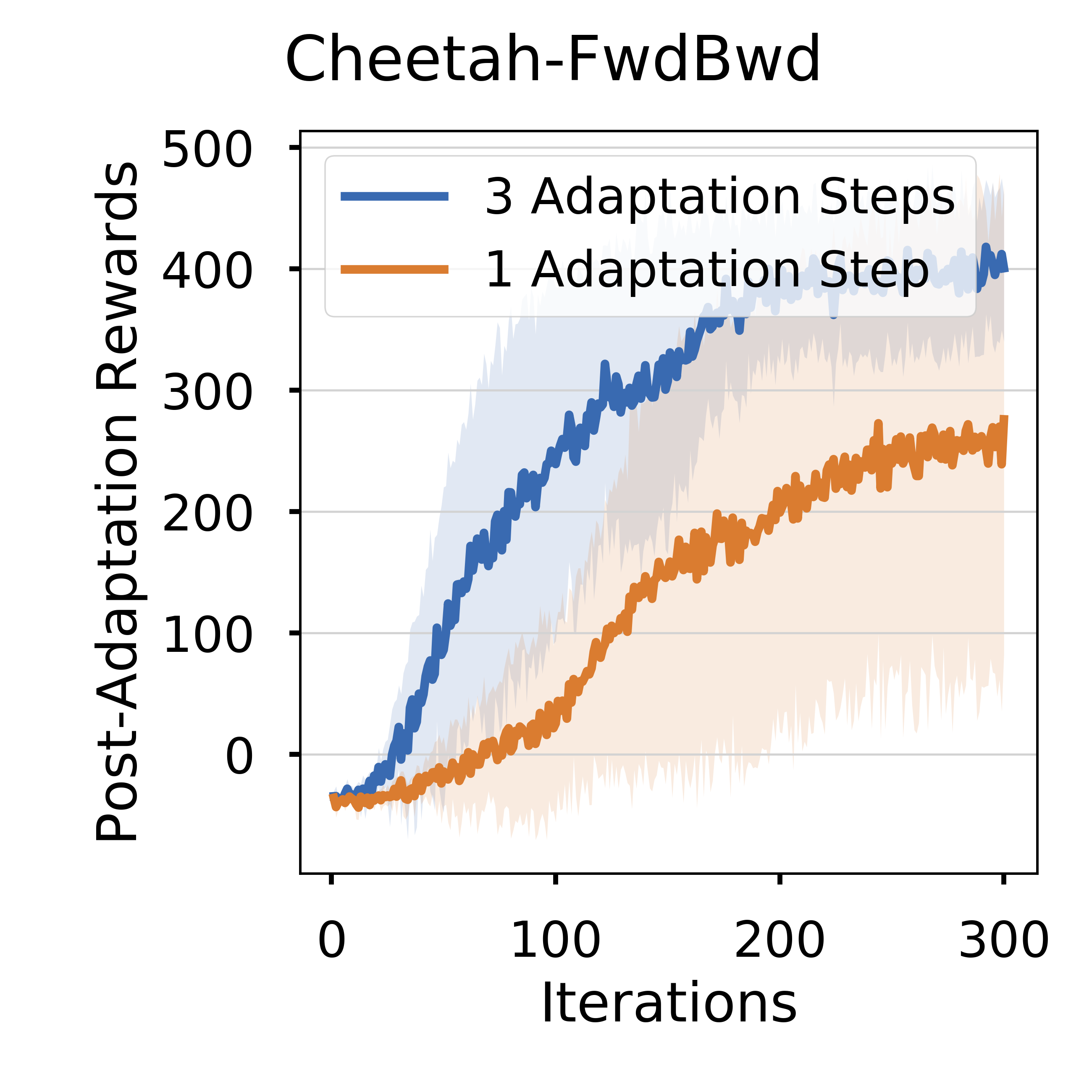
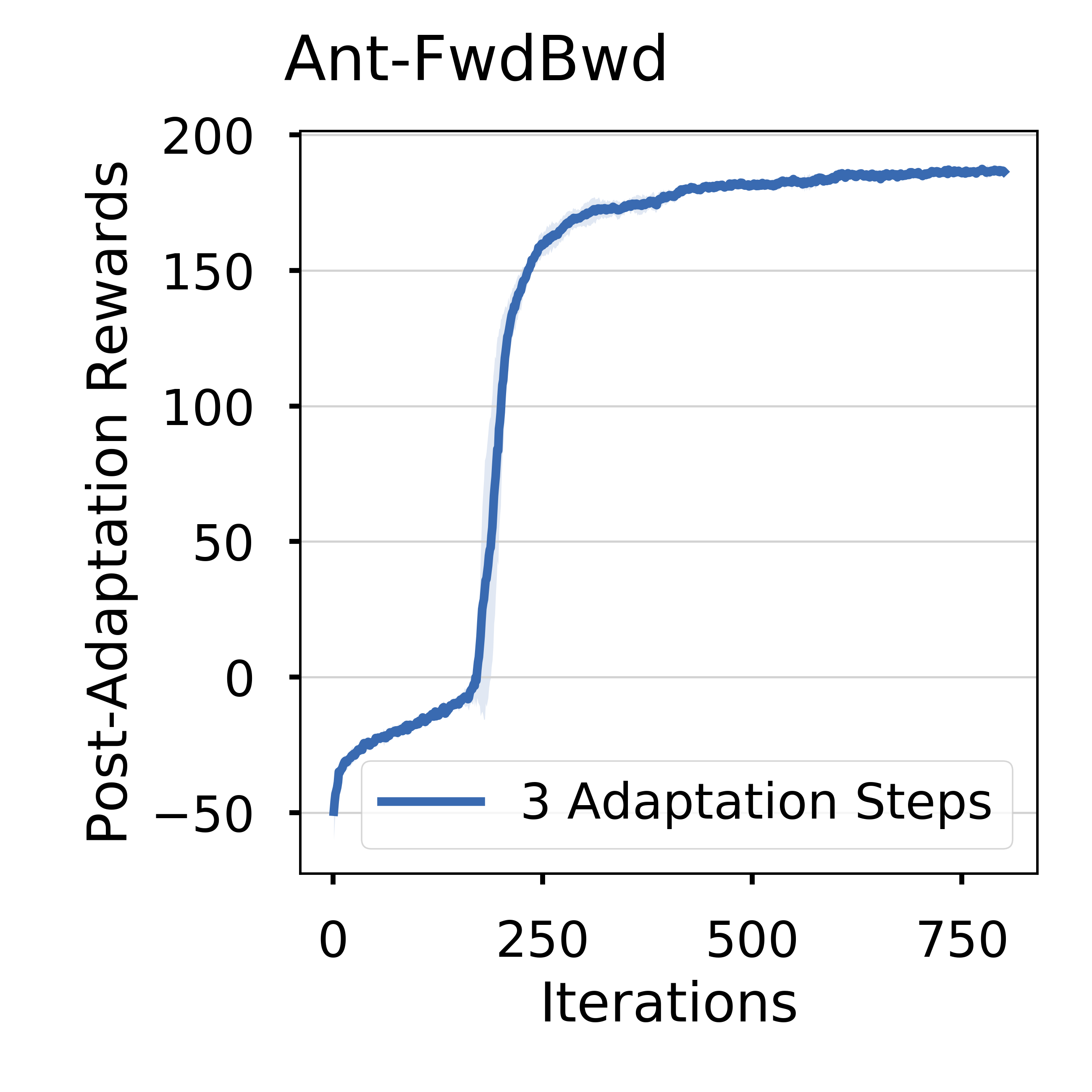
The above results are obtained by running maml_trpo.py on HalfCheetahForwardBackwardEnv and AntForwardBackwardEnv for 300 updates.
The figures show the expected sum of rewards over all tasks.
The line and shadow are the mean and standard deviation computed over 3 random seeds.
Info
Those results were obtained in August 2019, and might be outdated.